
Transaction Boundaries
Job Executor
A job is an explicit representation of a task to start process execution. A job is created when a timer event is approaching or a task is marked for asynchronous execution (see transaction boundaries). Thus, the processing of jobs can be divided into three phases:
- Job Creation
- Job Acquisition
- Job Execution
While jobs are created during process execution, the job executor plays the role of acquiring and executing tasks.
Job Creation
Jobs are created in Camunda for various purposes. Existing job types include:
- Asynchronous attributes when setting transaction boundaries in the process.
- Timer jobs - BPMN timer events.
- Asynchronous handling of BPMN events.
When created, a job can receive priority for delivery and execution.
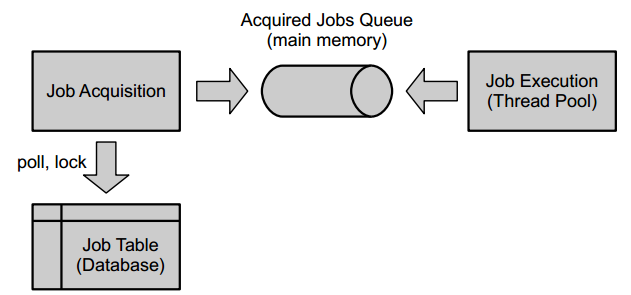
Job Acquisition
Job acquisition is the process of retrieving tasks from the database that should be executed next time. Therefore, tasks must be stored in the database along with properties defining the possibility of task execution. For instance, a job created for a timer event cannot be executed until a certain time interval has elapsed.
Jobs are stored in the database table ACT_RU_JOB. The table contains the following attributes:
Acquiring a Job
A job can be acquired if it meets the following conditions:
- It is due for execution, i.e., the value in the DUEDATE_ column is in the past.
- It is not locked, i.e., the value in the LOCK_EXP_TIME_ column is in the past.
- Retries have not been exhausted, i.e., the value in the RETRIES_ column is greater than zero.
Additionally, there is a notion of suspending a task within the process engine. For example, a task is suspended when the corresponding process instance is suspended. A job can be acquired only if it is not suspended.
Rules for Job Execution
Thread Pool
Delivered tasks are executed by a thread pool.
The thread pool selects tasks from the received tasks queue. The received tasks queue is an in-memory queue with a fixed capacity. When an executor starts executing a task, it is first removed from the queue.
Failed Job
In case of a job execution failure, for example, if invoking a service task throws an exception, the job will be retried multiple times (by default, 2 retries, a total of 3 executions). The retry does not happen immediately; the task is placed back into the acquisition queue. Upon retry, the value of the RETRIES_ column decreases, and the executor unlocks the task. Thus, the process engine keeps track of failed tasks. Unlocking also involves resetting the LOCK_EXP_TIME_ and LOCK_OWNER_ by setting both records to null. Subsequently, the task will be automatically retried as soon as it is unlocked. When the number of retries is exhausted (the value of the RETRIES_ column is 0), retry attempts cease, and a corresponding signal is sent to the process.
Despite all failed tasks being retried and the retry counter decreasing, there is an exception when this doesn't happen - optimistic locking.
Optimistic locking is a process of resolving conflicting updates to resources, for example, during parallel step execution.
After retries are exhausted, an incident is created.
Concurrent Job Execution
The Job Executor ensures that tasks from the same process instance are never executed concurrently.
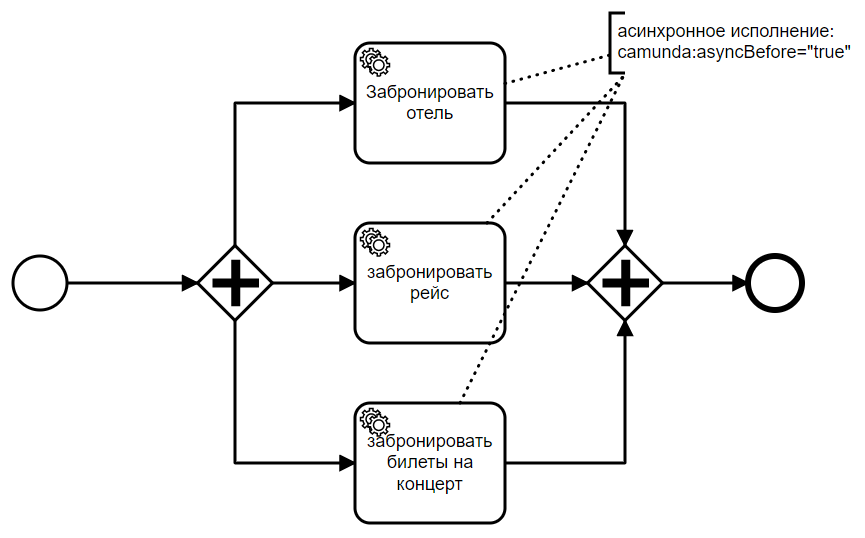
We have a parallel gateway followed by three service tasks executing asynchronously. As a result, three jobs are added to the database. Once a job appears in the database, it can be picked up by the job executor. It fetches jobs and delegates them to a thread pool, which actually processes the jobs.
This is generally good. However, it also presents an inherent problem: consistency. Consider a parallel join after the tasks. When the execution of a task finishes, we reach a parallel join and need to decide whether to wait for other tasks to finish or move on. This means, for each branch reaching the parallel join, we need to decide whether we can proceed or need to wait for one or more other executions from other branches.
This requires synchronization between the execution branches. This problem is solved using optimistic locking. Whenever a decision is made based on data that might be stale, the revision counter of the same database row is incremented in both transactions. Hence, the transaction that commits first (the parent) wins, and other transactions fail with an optimistic locking exception. The task that executes first and reaches the parallel gateway commits, while others fall under optimistic locking, and the revision counter of the parent task is incremented. As execution is initiated by a task, the job executor will recheck the condition after a certain wait time.
While this is an acceptable solution in terms of safety and consistency, such behavior is undesirable at a higher level, especially if the execution has non-transactional side effects that won't be rolled back by a failed transaction. For instance, if booking concert tickets belongs to another instance, multiple tickets might be booked upon task retry.
Understanding Camunda's ACID Transactions
During process execution, the Camunda engine will advance through the process steps until it reaches a wait state. Such a state could be one of:

- User tasks and message receive tasks.
- All intermediate catch events.
- An event-based gateway offering the option to react to one of several intermediate catching events.
- Some additional task types (service, DMN business rule, send task).
- External tasks. Message send events can also be implemented as external tasks.
In a wait state, any further process execution must wait for some trigger. Hence, wait states are always persisted to the database. However, you can control transaction boundaries by introducing additional checkpoints using async before and async after attributes. The job executor will ensure that the process execution continues asynchronously.
Transaction Boundary Control
Additional Wait States
Better control over transaction boundaries can be achieved by introducing additional save points at various process steps using async before and async after attributes. The process state will be persisted at such points, and the job executor will ensure that process execution continues asynchronously. Consider the diagram example below:

- User Task - has a mandatory wait point. After the creation of the user task, the process state will be saved and committed to the database. The process will wait for user interaction.
- Service Task - By default, it executes synchronously. In this case, if the service fails for some reason, the user task will need to be executed again.
- By setting
async before='true', the service task will execute asynchronously. This means, before executing this task, the process state will be saved and committed to the database.
Thus, if a transaction fails, the process execution will roll back to the last known save point. The re-execution of the faulty transaction will occur from the last save point (where async before='true' was set). Transaction boundaries can encompass more than one process step.
Make Every Service Task Asynchronous
An empirical rule, especially with a large number of service tasks, is to mark each task as asynchronous.
The downside is that such tasks slightly increase overall resource consumption. However, this approach has several advantages:
- The process stops at the task where an error occurred.
- A retry strategy can be configured for each service task.
- The ability to use various features for each service task.
Rules and Restrictions on Setting Save Points
In addition to the general strategy of marking service tasks as save points (SP), additional configuration of SP may be required.
Typical places to configure SP after, attribute async after="true":
-
 - allows users to complete their tasks without waiting for costly subsequent steps and without observing an unexpected rollback of the transaction to the waiting state before executing the user task;
- allows users to complete their tasks without waiting for costly subsequent steps and without observing an unexpected rollback of the transaction to the waiting state before executing the user task; -
 (non-idempotent actions) - ensures that irreversible changes, which should not occur more than once, do not accidentally repeat because subsequent steps may roll back the transaction to the SP long before the affected step. If the process can be invoked from other processes, SP should also be configured for end events;
(non-idempotent actions) - ensures that irreversible changes, which should not occur more than once, do not accidentally repeat because subsequent steps may roll back the transaction to the SP long before the affected step. If the process can be invoked from other processes, SP should also be configured for end events; -
(costly operations) - ensures that a computationally expensive step does not have to be repeated just because subsequent steps may roll back the transaction to the SP long before the affected step. If the process can be invoked from other processes, SP should also be configured for end events;
-
 (external event interception) - ensures that an external event, including message reception, is saved as soon as possible since any subsequent steps may roll back the transaction to the SP much earlier - the result of executing this step should not be lost;
(external event interception) - ensures that an external event, including message reception, is saved as soon as possible since any subsequent steps may roll back the transaction to the SP much earlier - the result of executing this step should not be lost;
Typical places to configure SP before, attribute async before='true':
-
 (start events) - SP allows rolling back actions when starting the process before anything is executed in the process instance;
(start events) - SP allows rolling back actions when starting the process before anything is executed in the process instance; -
(service tasks calling external systems) - SP allows separating a step with potential errors from other steps before it. In case of an error, the process instance will wait for its processing, which can be done in process monitoring;
-
 (parallel gateways) - parallel gateways synchronize individual branches of processes. If one of the branches reaches the parallel gateway before all others, the execution of that branch will roll back with an optimistic locking exception and will be re-executed later. Thus, such SP guarantees the synchronization of the execution of parallel branches performed by the Camunda job executor. It is worth noting that for actions within multiple instances, there is a special flag
(parallel gateways) - parallel gateways synchronize individual branches of processes. If one of the branches reaches the parallel gateway before all others, the execution of that branch will roll back with an optimistic locking exception and will be re-executed later. Thus, such SP guarantees the synchronization of the execution of parallel branches performed by the Camunda job executor. It is worth noting that for actions within multiple instances, there is a special flagmulti-instance asynchronous after.
SP before cannot be configured in the following cases:
-
 - user tasks and other wait state steps;
- user tasks and other wait state steps; -
(as well as steps - external tasks) - such SP creates unnecessary overhead as they complete the transaction by themselves;
-
 (various gateways) - there is no need to use SP for such steps unless the gateway has no configured "listener" that may fail.
(various gateways) - there is no need to use SP for such steps unless the gateway has no configured "listener" that may fail.
Transaction Rollback Without Error Handling
Every unhandled exception that occurs during process execution rolls back the transaction to the SP. The image shows an example:
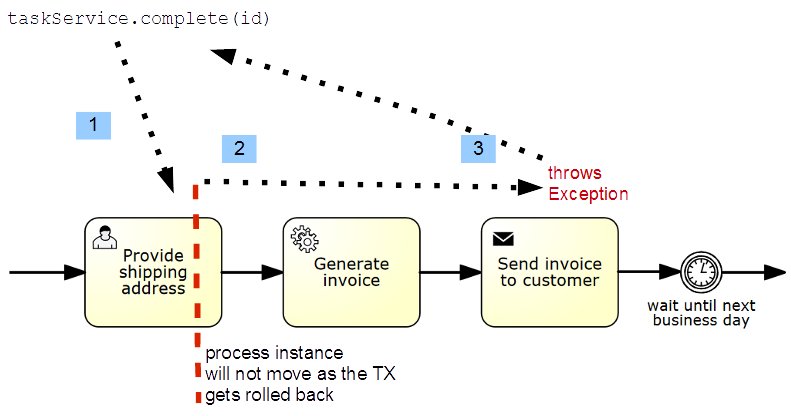
- Execution of a user task takes place.
- After the task is executed, the process execution continues until it reaches a wait state (SP) - a timer.
- In case an unhandled exception occurs, the transaction rolls back, and the completed user task remains unfinished.
In this situation, the process will be stuck because the execution of the user task becomes impossible. To solve the problem in this example, set the asyncBefore='true' flag for the service task.
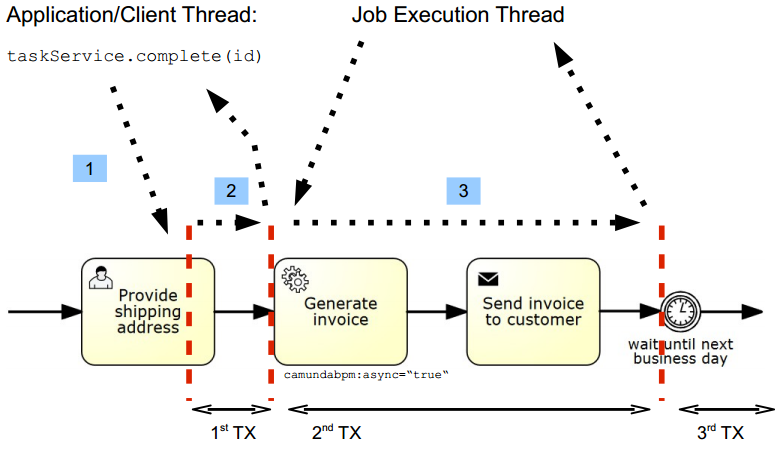
In this case, the rollback of the user task will not occur, and the job executor will retry the failed transaction from the "Generate invoice" step after some time.
Sometimes, transaction rollback is necessary in the process. For example:
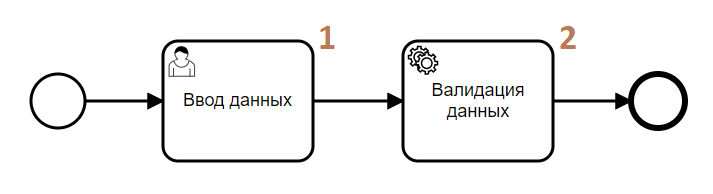
- The user enters data on a form.
- During the validation of the entered data, a problem is detected, and an exception is thrown, which rolls back the transaction and allows entering the data again.