
Business Process Optimization Practices
This article outlines step-by-step instructions on what steps to take to optimize the operation of your process.
Process optimization involves several basic approaches:
- microservice interaction with your process in Kafka;
- business logic of the process;
- database of your microservice;
- JVM settings;
- preparation for load testing;
- issues and solutions.
Working with Kafka
If your service works with Kafka, you need to define certain criteria for its operation.
By default, a Kafka batch consists of 500 messages, and if your process fails to process these 500 messages within the default 5 minutes, the entire batch will be dropped into the lag and processed again. This behavior of your process will duplicate business entities that essentially should not exist, as, for example, the same initial message can be processed multiple times.
Therefore, depending on the throughput of your process, you need to configure the batch parameters and its processing speed. In standard cases, this should not happen, but be prepared that a couple of thousand messages may come to Kafka, and your process should be ready for them.
To increase the number of threads for working with Kafka, you can configure: KAFKA_CONCURRENCY:20 (default is 10 threads)
Business Process Logic
The first thing to do is to get rid of JavaScript cubes. Rewrite using Groovy, which will give a power boost of 30%.
First of all, you should deal with threads and context save points - waiting points.
Save points are a tool for changing thread behavior and scaling the process instance. The more you use it, the more work the task executor will perform, which is a key component to pay attention to when you want to improve the performance of your system.
The task executor's configuration is usually weak by default and
Exclusive (opens in a new tab) tasks are used in Camunda by default - this means that only one task is always executed in parallel for one process instance. This is a safety net that allows avoiding optimistic lock exceptions, as multiple parallel paths may conflict when writing to the same database row.
You can change this configuration to run tasks of one process instance in parallel if you are sure you are not creating optimistic lock exceptions due to a suitable process structure. Additionally,
Keep in mind that parallel task processing and a large number of optimistic lock exceptions incur overhead and can slow down your system. Using parallel processing features is not recommended for most use cases, as it complicates the work and requires careful testing when done.
Task Executor (Asynchronous Process Execution)
The task executor configuration is absent, which is generally reasonable. Configuration options and default values:
camunda.bpm.job-execution.core-pool-size: 3 // Number of threads for task execution
camunda.bpm.job-execution.max-pool-size: 5 // Number of tasks that can be queued in memory, waiting for an available execution thread.
camunda.bpm.job-execution.max-jobs-per-acquisition: 3 // How many jobs to acquire at once
camunda.bpm.job-execution.max-wait: 5000 // Maximum wait time for job acquisition
camunda.bpm.job-execution.max-wait.max-pool-size: 3 // Number of threads in which jobs are processed
camunda.bpm.job-execution.wait-time-in-millis: 1000 // Minimum wait time for job acquisition increases exponentially if there are no jobs, up to the maximum time
camunda.bpm.job-execution.lock-time-in-millis: 300000 // Timeout for job lockingMeaningful configuration should balance these values according to the given situation. To make adjustments, understanding some basics is necessary:
- There's no point in having more active threads than the CPU cores can directly handle. Otherwise, threads will simply swap places, hindering efficient computations.
- Every time a thread gets blocked, the process waits for the completion of some database operation. It's not active, and the CPU won't be engaged.
If you want to figure out how many threads you can assign to the job executor (camunda.bpm.job-execution.core-pool-size), you need to know how many threads are available overall and how many threads are already used by other thread pools. The more components you run on your machine, the harder it becomes to predict CPU free power. This is also true for virtualized environments where shared resources are used.
You should also consider the business logic of your processes: are you
Bear in mind that scaling a microservice on BPM increases the load on underlying services and systems (DB, Kafka, REST), so you may need to limit it to avoid crashes of infrastructural components.
When increasing the number of threads, ensure the size of the internal queue (camunda.bpm.job-execution.max-pool-size) has also been increased, or it may become empty, and threads won't receive new jobs to execute. On the other hand, the queue shouldn't be too large. In a cluster, having overly large queue sizes (camunda.bpm.job-execution.max-jobs-per-acquisition) can result in camunda.bpm.job-execution.lock-time-in-millis), jobs expire by timeout and will be executed twice (one of which triggers an optimistic lock exception).
A typical performance tuning approach:
- start with the number of threads = CPU cores * 1.5;
- gradually increase the queue size until throughput stops, as all threads are "busy" waiting for I/O operations;
- increase working threads, then queue size - always check if it improves throughput;
- each time you hit the limit, you find your upper limit of configuration, which is typically optimal for the working environment.
Database of Your Microservice
The I/O time of data (for writing changes, instance state) into tables depends on your use case. The key factors are:
- complexity of process models — measured by the number of save points (red bars at the beginning and end of a cube in the process designer);
- number of running process instances — measured per unit of time;
- data attached to process instances (also known as process variables), measured in bytes (process monitoring shows info regarding these);
- average duration of process instances, as the longer they need to execute (and thus wait in a steady state), the fewer database traffic their total number of save points per unit of time causes, but the more data you store in the runtime database.
Queries and reads' performance from runtime tables are most affected by process variables/business data. For each process variable used in a query, there is a SQL join, affecting performance.
The number of database connections affects process performance. When capturing a dump, it was observed that the thread waits for a free connection to process the process in the database.
By default, the number of connections is set to HIKARI_MAXIMUM_POOLSIZE: 10, and this configuration can be modified.
By configuring the job executor, the database can become a bottleneck when handling high load processes. A straightforward approach is to
If neither is possible or insufficient, check if the database load can be reduced through changes in your process. Thus, analyzing the root cause of the load is necessary. It's recommended to separate the database in such a way that you can see the load data for runtime, history, and especially the table containing byte arrays. Two typical conclusions:
- history holds a lot of data, for instance, because you execute many tasks and update many variables. In this case, a good strategy is disabling history to reduce data volume;
- large chunks of data are stored in the byte array table mainly because you store too much data as process variables, such as large XML or JSON structures. Camunda always updates a complete process variable, even if you only change some attributes or add rows to a list that's part of the data structure. Furthermore, the entire fragment is also written into history to preserve the history of variable values. In this scenario, it's much more efficient to store business data as a separate structured object or in a more suitable storage (e.g., document database). In this case, Camunda only stores a reference, relieving the database from heavy load.
Camunda batches SQL operators of the current invocation and runs them at once at the end of the transaction. Depending on the nature of the process model and work done in that transaction, this batch can become large.
JVM Settings
Usually, it's not required to configure the Java Virtual Machine (JVM). It's better to focus on the strategies outlined in this article.
If you have hints of memory issues, garbage collector problems, or thread locking, you should connect a Grafana monitor to actuator metrics and observe the service's behavior.
Preparation for Load Testing
If you are uncertain whether BPMPLAYER can handle specific load requirements, you should conduct load testing.
Usually, this involves the following stages:
- prepare an
environment as close as possible to the production one, otherwise, the results may be biased; - prepare specific processes you want to run, such as realistic BPMN processes for your use case. If you usually run synchronous service tasks, do it in processes. If you have large payloads, use them. If you use multi-instance tasks, ensure your scenario includes them as well;
- define
clear goals for load testing, for example, you may need to run at least 1000 instances of a working process per second; - prepare
load generation , which is not always simple, as you need to stress your system in a way you can't achieve with a single straightforward client; - prepare
monitoring for analyzing the situation if issues arise.
Typical monitoring and profiling tools to use:
- Core tools available with Java installation:
- Grafana
- Prometheus
- JVM thread dumps
- Commercial offerings
- JMeter
- Java Mission Control
Typical load generation tools our clients use:
- JMeter
- Postman
- SOAP Interface
Java memory consumption, especially garbage collection and potential memory leaks, often result from issues with surrounding components.
These problems can be detected by checking which objects consume a lot of memory, using a JVM observation tool.
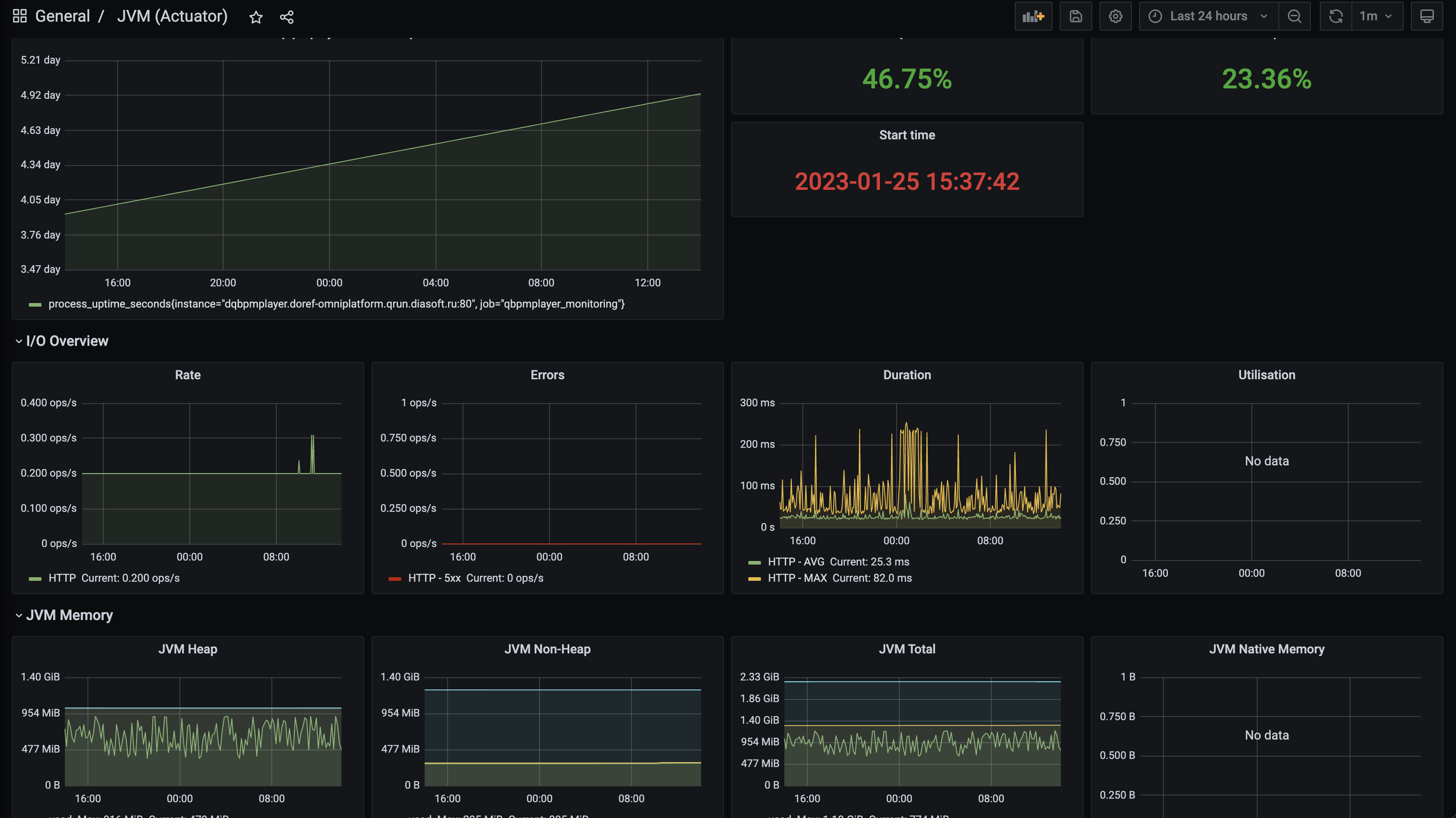
Monitor database load to avoid overloading it. Sometimes it's better to reduce the number of connections in the connection pool.
If your process involves Kafka, Grafana monitoring should also be configured.
Gathering Information for Troubleshooting
Initially, we need a problem-solving strategy. Take a moment to think about the principles you'll apply to solve acute and general performance issues. Here are some questions to ask for root cause analysis:
- What makes you think there is a performance issue?
- Has this system ever worked well?
- What has changed recently? (Software, Hardware)
- Can the performance degradation be expressed in terms of latency or execution time?
- Does the issue affect other people or applications (or just you)?
- What is the surrounding environment?
- What software and hardware are used?
- Versions?
- Configuration?
When dealing (suspecting) with issues, delve deeper into detailed information about jobs, information that can be extracted from the database table act_ru_job:
Number of completed jobs - how many jobs are currently received/locked, meaning they are currently being executed?Cluster distribution - how are executing jobs distributed across the namespace? Identify the lock owner, which is recorded in the database.Number of jobs not yet executed - how many jobs currently need to be executed, meaning their due date has been reached or no due date is set, but they haven't been acquired? These are jobs that should be executed. Usually, their count should be close to zero. Monitor the number over time; if it remains above a certain threshold, you have a bottleneck. In this situation, you might even suffer from "job starvation" as Camunda does not apply FIFO principle for job execution. This situation needs resolution. A typical scenario is experiencing this overload only at peak times and resolving it during off-peak times.
When facing resource shortages. If this occurs, clustering is a very natural choice to address the problem. But in most cases, processes built on Camunda will often wait for input/output (database, remote service calls, etc.). To properly address overload issues, you must analyze the root cause:
- Key system metrics for your Camunda application and database. Visualize them in Grafana!
- CPU load
- Memory usage
- I/O
- Response time
Often, there is no possibility to get metrics from the database due to security restrictions. In this case, try to measure the response time from the database as an indicator of its performance.
- Database information
- Slow query log
- Other usage information, depending on the specific database product. Best approach, consult your database administrator.
Collecting this information usually gives a good idea of which component is genuinely busy and causing the bottleneck.
Bottleneck Identified!
Having an understanding of the bottleneck, you should develop the right tuning strategy. However, system behavior is very complex, and experience shows that multiple attempts are required to improve the situation. This is normal and not a problem, but it's important to follow a systematic approach to troubleshoot overload issues.
The basic strategy is simple:
- Set up tests and take measurements that will give you a baseline to compare against.
- Change settings, but it's best to change one parameter at a time.
- Measure again and compare with the baseline to understand how the change improved the situation.
Tuning for resources like the job executor thread pool, start with small numbers and incrementally increase them. If you start with too large a value, you have to check two measurements at once: increasing and decreasing.
Guesswork can lead to incorrect conclusions. It is recommended to set up the load testing environment and generate load to saturate all resources. This allows you to optimize your system according to your specific load scenario. It is challenging, especially because you usually have to simulate service calls, thus simulating realistic response times.
A good compromise is often:
- Monitor the load on your production systems (as mentioned above, e.g., through database queries).
- Change settings and check the impact over time. Note: The above-described approach is practical. Production load can vary significantly, so plan enough time to allow regression to the mean and monitor other performance indicators, such as process instances, to realistically evaluate results.
Problems and Solutions
Below are common scenarios that could potentially cause issues. Be sure to read the section on Handling Data in Processes (opens in a new tab) to understand best practices for working with potential data flows and business data in QBPM.
Performance Decreases After Saving Large Files as Variables
Problem:
- Selecting BLOB leads to massive memory allocation.
- Operations become more costly (e.g., VACUUM).
- Replication becomes slower.
Solution:
- Store large files in a dedicated third-party CMS.
- Save a reference to the file only as a variable in Camunda.
In the Database, the Variable Size Exceeds 4000 Characters
Problem:
- When saving string-type variable values, the character limit for Postgres is 4000.
Solution:
- Reduce the length of the value.
- Save the string as an object in Postgres.
Optimistic Locking Exceptions Occur When Updating Variables Using the API
Problem:
- The same variables are updated by multiple workers, consequently updating the same row in the database.
Solution:
- Use the local API when updating variables. You should combine this with input/output mappings to have access to variables in subsequent actions.