
Практики оптимизации бизнес-процесса
В данной статье пошагово расписаны какие шаги необходимо сделать для оптимизации работы вашего процесса.
Оптимизация процесса стоит из нескольких базовых подходов:
- работа микросервиса с вашим процессом в Кафке;
- бизнес логика процесса;
- база данных вашего микросервиса;
- настройки JVM;
- подготовка к нагрузочному тестированию;
- проблемы и решения.
Работа с Кафкой
Если ваш сервис работает с кафкой необходимо определить некоторые критерии ее работы.
По умолчанию в кафке пачка состоит из 500-ста сообщений и если ваш процесс не успеет обработать эти 500 сообщений за отведенные 5 минут по умолчанию вся пачка будет скинута в лаг и обработана повторно. Такое поведение вашего процесса будет дублировать бизнес сущности, которые по сути существовать не должны, так как например одно и тоже стартовое сообщение может быть обработано несколько раз.
Поэтому в зависимости от пропускной способности вашего процесса необходимо сконфигурировать параметры пачки и скорость ее обработки. В стандартных кейсах такого быть не должно, но будьте готовы, что в кафку придет пару тысяч сообщений и ваш процесс должен быть готов к ним.
Для увеличения кол-во потоков для работы с кафкой можно настроить: KAFKA_CONCURRENCY:20 - (по умолчанию 10 потоков)
Бизнес логика процесса
Первое, что стоит сделать - избавиться от кубиков с JavaScript. Переписать с использованием языка Groovy, что даст прирост мощности в 30%.
Для начала, стоит разобраться с потоками и точками сохранений контекста - точек ожидания.
Точки сохранения — это инструмент для изменения поведения потоков и масштабирования экземпляра процесса. Чем больше вы его используете, тем больше работы будет выполнять исполнитель задания, который является ключевым компонентом, на который следует обратить внимание, когда вы хотите улучшить производительность вашей системы.
Конфигурация исполнителя заданий по умолчанию обычно слабая и
Эксклюзивные (opens in a new tab) задания используются в Camunda по умолчанию - это означает, что для одного экземпляра процесса всегда параллельно выполняется только одно задание. Это защитная сетка, позволяющая избежать оптимистичных исключений блокировки, поскольку несколько параллельных путей могут конфликтовать при записи в одну и ту же строку базы данных.
Вы можете изменить эту конфигурацию, чтобы запускать задания одного экземпляра процесса параллельно, если вы уверены, что не создаете оптимистичные исключения блокировок из-за подходящей структуры процесса. Кроме того,
Имейте в виду, что параллельная обработка заданий и большое количество исключений оптимистичных блокировок вызывают накладные расходы и могут замедлить работу вашей системы. Использование функций параллельной обработки не рекомендуется для большинства случаев использования, так как это усложняет работу и требует тщательного тестирования в тех случаях, когда это делается.
Исполнитель заданий (асинхронное выполнения процесса)
Конфигурация исполнителя заданий отсутствует, что в общем-то разумно. Варианты конфигурации и значения по умолчанию:
camunda.bpm.job-execution.core-pool-size: 3 // Количество потоков обработки заданий
camunda.bpm.job-execution.max-pool-size: 5 // Количество заданий, которые можно поставить в очередь в памяти, ожидая, пока поток выполнения станет доступным.
camunda.bpm.job-execution.max-jobs-per-acquisition: 3 // сколько заданий взять за раз
camunda.bpm.job-execution.max-wait: 5000 // максимальное время опроса Заданий
camunda.bpm.job-execution.max-wait.max-pool-size: 3 // кол-во потоков в котором обрабатываются задания
camunda.bpm.job-execution.wait-time-in-millis: 1000 // минимальное время опроса работы повышается по exp, если заданий нету максимальное время
camunda.bpm.job-execution.lock-time-in-millis: 300000 // тайм-аута блокировкиОсмысленная конфигурация должна сбалансировать эти значения в соответствии с данной ситуацией. Чтобы делать настройки, нужно понимать некоторые основы:
- нет смысла иметь больше активных потоков, чем могут напрямую обрабатывать ядра ЦП. В противном случае потоки просто будут меняться местами и мешать эффективным вычислениям;
- всякий раз, когда поток блокируется, процесс ожидает завершения какой-либо операции с базой данных, он не активен и ЦП не будет этим заниматься.
Если вы хотите выяснить, сколько потоков вы можете назначить исполнителю заданий (camunda.bpm.job-execution.core-pool-size), вам нужно знать, сколько потоков доступно в целом и сколько потоков уже используется другими пулами потоков. Чем больше компонентов вы запускаете на своей машине, тем сложнее предсказать свободную мощность ЦП. Это также верно для виртуализированных сред, в которых используются общие ресурсы.
Вы также должны подумать о бизнес логике ваших процессов: выполняете ли
Имейте в виду, что масштабирование микросервиса на bpm увеличивает нагрузку на нижестоящие службы и системы (БД, кафка, REST), поэтому может потребоваться ограничить его, чтобы избежать падений данных инфраструктурных компонентов.
При увеличении количества потоков убедитесь, что был увеличен размер внутренней очереди (camunda.bpm.job-execution.max-pool-size), иначе она может быть пустой, и потоки не получат новых заданий для выполнения. С другой стороны, очередь не должна быть слишком большой. В кластере camunda.bpm.job-execution.max-jobs-per-acquisition) могут привести к тому, что camunda.bpm.job-execution.lock-time-in-millis), то задания истекают по тайм-ауту и будут выполняться дважды (одна из которых сработает в исключении оптимистичной блокировки).
Типичный подход к настройке производительности:
- следует начать с количества потоков = ядер ЦП * 1,5;
- постепенно увеличить размер очереди до тех пор, пока пропускная способность не прекратится, потому что все потоки «заняты» в ожидании операций ввода-вывода;
- увеличить рабочие потоки, а затем размер очереди - всегда проверяйте, улучшает ли это пропускную способность;
- всякий раз, когда вы достигаете предела, вы находите свой верхний предел конфигурации, который обычно оптимален для рабочей среды.
База Данных вашего микросервиса
Время ввода-вывода данных (для записи изменений, состояния экземпляров процесса) в таблицы зависит от вашего варианта использования. Ниже приведены основополагающие факторы:
- сложность моделей процессов — измеряется количеством точек сохранения (красные полосы в начале и конце кубика в дизайнере процессов);
- количество запущенных экземпляров процесса — измеряется в единицу времени
- данные, прикрепленные к экземплярам процесса (также называемые переменными процесса), измеряются в байтах (в мониторинге процесса выводится информация и по ним);
- средняя продолжительность экземпляров процесса, поскольку чем дольше они должны выполняться (и, следовательно, ждать в постоянном состоянии), тем меньше трафика базы данных вызывает их общее количество точек сохранения в единицу времени, но тем больше данных вы храните в базе данных времени выполнения.
На производительность запросов и чтения из таблиц среды выполнения больше всего влияют переменные процесса/бизнес-данные. Для каждой переменной процесса, используемой в запросе, требуется объединение на уровне SQL, что влияет на производительность.
Кол-во коннектов к базе данных влияет на производительность процесса. При снятии дампа наблюдалось, что поток ждет свободного коннекта для обработки процесса в базе.
По умолчанию кол-во коннектов HIKARI_MAXIMUM_POOLSIZE:10, данную настройку можно изменить.
Настроив исполнитель заданий, база данных может стать узким местом при обработке процессов с высокой нагрузкой. Очень простой подход состоит в том, чтобы
Если и то, и другое невозможно или недостаточно, проверьте, можно ли уменьшить нагрузку на базу данных за счет изменений в вашем процессе. Поэтому нужно проанализировать первопричину нагрузки. Рекомендуется разделить базу данных таким образом, чтобы вы могли видеть данные загрузки для среды выполнения, истории и, в частности, таблицы, содержащей массивы байтов. Два типичных вывода:
- в историю записывается много данных , например, потому что вы выполняете множество задач и обновляете множество переменных. В этом случае хорошей стратегией является отключение истории для уменьшения объема данных;
- большие куски данных записываются в таблицу массива байтов, в основном потому, что вы сохраняете слишком много данных в виде переменных процесса, таких как большие структуры XML или JSON. Camunda всегда обновляет одну переменную процесса целиком, даже если вы меняете только некоторые атрибуты или добавляете строки в список, являющийся частью структуры данных. Кроме того, весь фрагмент также записывается в историю, чтобы сохранить историю значений переменных. В этом сценарии гораздо эффективнее хранить бизнес-данные в виде отдельного структурированного объекта или в более подходящем хранилище (например, в базе данных документов). В таком случае Camunda сохраняет только ссылку и освобождается от большой нагрузки на базу данных.
Camunda группирует операторы SQL текущего вызова и запускает их сразу в конце транзакции. В зависимости от характера модели процесса и работы, проделанной в этой транзакции, этот пакет может стать большим.
Настройки JVM
Обычно не требуется настраивать виртуальную машину Java (JVM). Лучше сосредоточиться на стратегиях, описанных в этой статье.
Если у вас есть намеки на проблемы с памятью, проблемы с сборщиком мусора или блокировку потоков, вам следует подключить монитор grafana на метрики actuator и посмотреть как ведет себя сервис.
Подготовка к нагрузочному тестированию
Если вы сомневаетесь, сможет ли BPMPLAYER справиться с определенными требованиями к нагрузке, вам следует провести нагрузочное тестирование.
Обычно это включает в себя следующие этапы:
- подготовьте
среду , максимально приближенную к рабочей, иначе результаты могут быть необъективными; - подготовьте конкретные процессы, которые вы хотите запустить, например реалистичные для вас рабочие процессы BPMN. Если вы обычно запускаете синхронные сервисные задачи, сделайте это в процессах. Если у вас есть большие полезные нагрузки, используйте их. Если вы используете задачи с несколькими экземплярами, убедитесь, что ваш сценарий также содержит их;
- определите
четкие цели для нагрузочных тестов, например, вам может потребоваться запускать не менее 1000 экземпляров рабочего процесса в секунду; - подготовьте
генерацию нагрузки , что не всегда просто, так как вы должны нагрузить свою систему таким образом, что вы не можете сделать с помощью одного простого клиента - подготовьте
мониторинг для анализа ситуации, если у вас возникнут проблемы.
Типичные инструменты мониторинга и профилирования, которые необходимо использовать:
- Основные инструменты, доступные при установке Java:
- Grafana
- Prometheus
- Дампы потоков JVM
- Коммерческие предложения
- Jmetter
- Java Mission Control
Типичные инструменты генерации нагрузки, которые используют наши клиенты:
- JMeter
- Почтальон
- SOAP-интерфейс
Потребление памяти Java, особенно сборка мусора и потенциальные утечки памяти, часто происходят из-за проблем с окружающими компонентами.
Эти проблемы можно обнаружить, проверив, какие объекты занимают много памяти, с помощью инструмента наблюдения JVM.
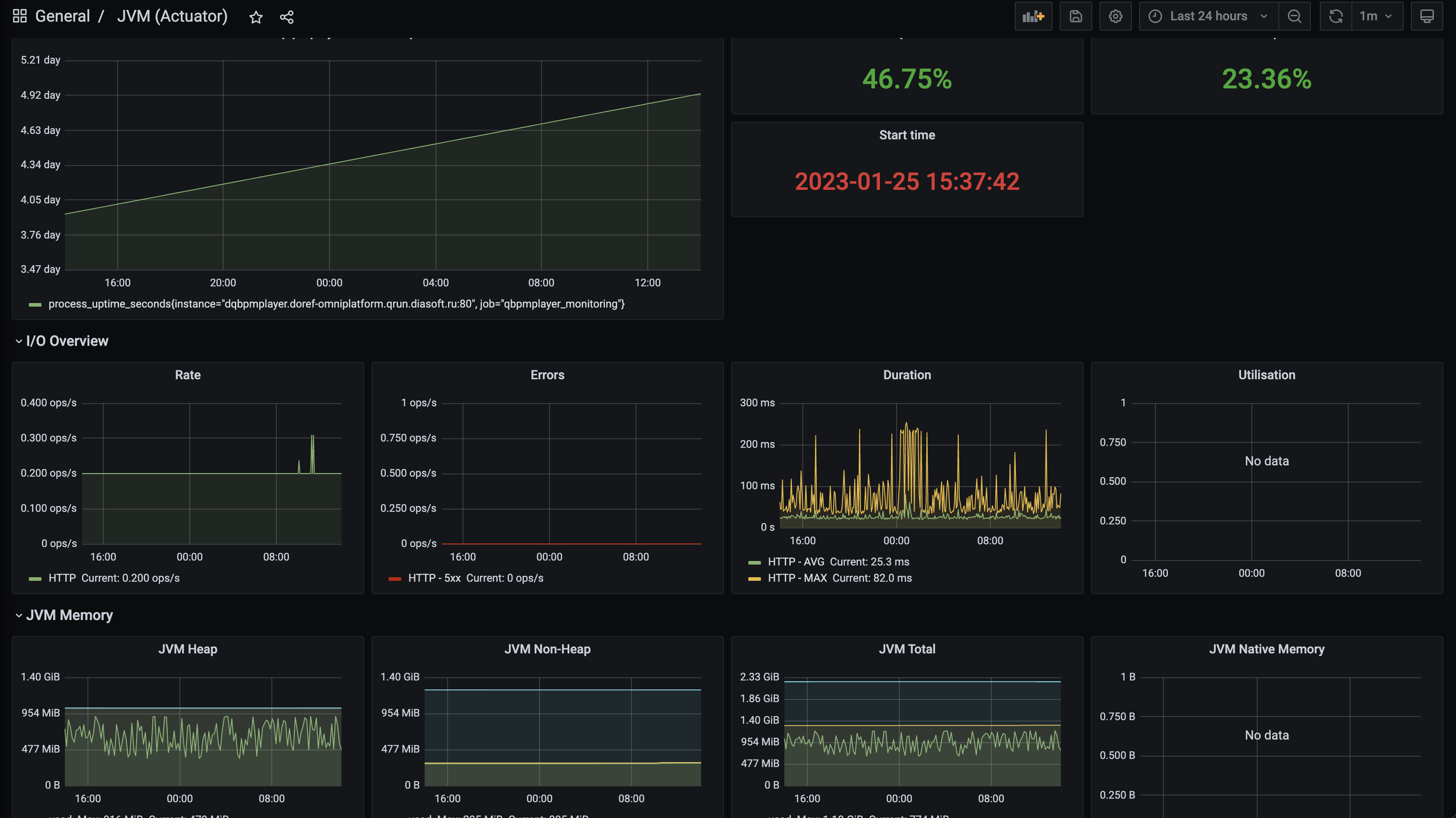
Контролируйте нагрузку на базу данных, чтобы избежать перегрузки базы данных. Иногда лучше уменьшить количество подключений в пуле подключений.
Если в вашем процессе используются кафка, то монитор графаны тоже необходимо настроить.
Сбор информации для разбора полетов
Изначально нам нужна стратегия решения проблем. Потратьте минутку, чтобы подумать о том, какие принципы вы будете применять для решения острых и общих проблем с производительностью. Ниже приведены некоторые вопросы, которые следует задать для анализа первопричины:
- Что заставляет вас думать, что есть проблема с производительностью?
- Эта система когда-либо работала хорошо?
- Что изменилось за последнее время? (Программное обеспечение, Аппаратное обеспечение)
- Можно ли выразить ухудшение производительности в терминах задержки или времени выполнения?
- Затрагивает ли проблема других людей или приложения (или только вас)?
- Что такое окружающая среда?
- Какое программное и аппаратное обеспечение используется?
- Версии?
- Конфигурация?
Когда сталкиваемся (подозреваем) c проблемами, следует глубже изучить подробную информацию о заданиях (job), информацию о которых можно извлечь из БД таблицаact_ru_job:
Кол-во выполненных заданий - сколько заданий в настоящее время получено/заблокировано, что означает, что они выполняются в данный момент?Распределение кластера - как выполняемые задания распределяются по неймспейсу? Определить владельца блокировки, который прописывается в базе данных.Кол-во еще не выполненных заданий - сколько заданий в настоящее время должны быть выполнены, что означает, что срок выполнения достигнут или срок выполнения не установлен, но не получен? Это задания, которые должны быть выполнены. Обычно их количество должно быть близко к нулю. Зафиксируйте число с течением времени, если оно остается выше определенного порога, у вас есть узкое место. В этой ситуации вы можете даже пострадать от "голодания" заданий, поскольку Camunda не применяет принцип FIFO для выполнения заданий. Эту ситуацию необходимо разрешить. Типичная картина состоит в том, чтобы испытывать эту перегрузку только в пиковое время дня и разрешать ее в спокойное время.
Когда сталкиваемся с нехваткой ресурсов. Если это произойдет, кластеризация — очень естественный выбор для решения проблемы. Но в большинстве случаев процессы, построенные на Camunda, чаще всего будут ожидать ввода-вывода (база данных, удаленные вызовы службы и т. д.). Чтобы правильно решить проблемы с перегрузкой, вы должны проанализировать первопричину:
- Основные системные метрики для вашего приложения Camunda и базы данных. Постройте их в grafana!
- Загрузка процессора
- Использование памяти
- Ввод/вывод
- Время отклика
Часто нет возможности получить метрики из базы данных из-за ограничений безопасности. В этом случае следует попытаться измерить время отклика от базы данных как показатель ее работоспособности.
- Информация о базе данных
- Журнал медленных запросов
- Другая информация об использовании, в зависимости от конкретного продукта базы данных. Лучший подход к вашему администратору баз данных.
Сбор этой информации обычно дает хорошее представление о том, какой компонент действительно занят и вызывает узкое место.
Узкое место найдено!
Имея представление об узком месте, следует выработать правильную стратегию настройки. Однако поведение системы очень сложное, и опыт показывает, что для улучшения ситуации требуется несколько попыток. Это нормально и не является проблемой, но важно следовать систематическому подходу для решения проблем с перегрузкой.
Основная стратегия проста:
- Настройте тесты и проведите измерения, которые дадут вам базовый уровень, с которым вы сможете сравнить.
- Меняйте настройки, но лучше всего по одному параметру.
- Измерьте еще раз и сравните с эталоном, чтобы понять насколько изменение улучшило ситуацию.
Настройку для таких ресурсов, как пул потоков исполнителя заданий, начните с небольших чисел и увеличивайте их. Если начнете со слишком большого значения, то приходется проверять сразу два измерения: возрастающее и убывающее.
Угадывание может привести к неверным выводам. Рекомендуется настроить среду нагрузочного тестирования и сгенерировать нагрузку, чтобы все ресурсы были заняты. Это позволяет оптимизировать вашу систему в соответствии с вашим конкретным сценарием нагрузки. Это сложно, особенно потому, что обычно приходится имитировать вызовы службы, а значит имитировать реалистичное время отклика.
Хорошим компромиссом часто является:
- Контролировать нагрузку на свои производственные системы (как указано выше, например, с помощью запросов к базе данных).
- Изменить настройки и проверить влияние с течением времени. Примечание: описанный выше подход является практическим. Производственная нагрузка может сильно различаться, поэтому запланируйте достаточно времени, чтобы позволить регрессию к среднему значению, и следите за другими показателями производительности, такими как экземпляры процесса, чтобы реалистично оценивать результаты.
Проблемы и решения
Ниже приведены распространенные сценарии, которые потенциально могут вызвать проблемы. Обязательно прочитайте раздел об обработке данных в процессах (opens in a new tab), чтобы понять лучшие варианты работы с потенциальными потоками данных и бизнес-данными в QBPM.
Производительность снижается после сохранения больших файлов в качестве переменных
Проблема:
- Выбор BLOB приводит к огромному выделению оперативной памяти
- Операции становятся более дорогостоящими (например, ВАКУУМ)
- Репликация становится медленнее
Решение:
- Хранить большие файлы в выделенной сторонней CMS
- Сохранять ссылку на файл только как переменную в Camunda
В БД размер переменной превышает 4000 символов
Проблема:
- При сохранении значений переменных строкового типа ограничение на количество символов для Postgres составляет 4000.
Решение:
- Уменьшить длину значения.
- Сохранить строку как объект в Postgres.
Исключения оптимистической блокировки возникают при обновлении переменных с помощью API
Проблема:
- Одни и те же переменные обновляются несколькими рабочими, следовательно, обновляется одна и та же строка в БД.
Решение:
- Используйте локальный API при обновлении переменных. Вы должны комбинировать это с отображениями ввода/вывода, чтобы иметь доступ к переменным в последующих действиях.